Gemini Omni:谷歌用「世界模型」填了 Sora 的坑,顺手把视频生成的天花板掀了
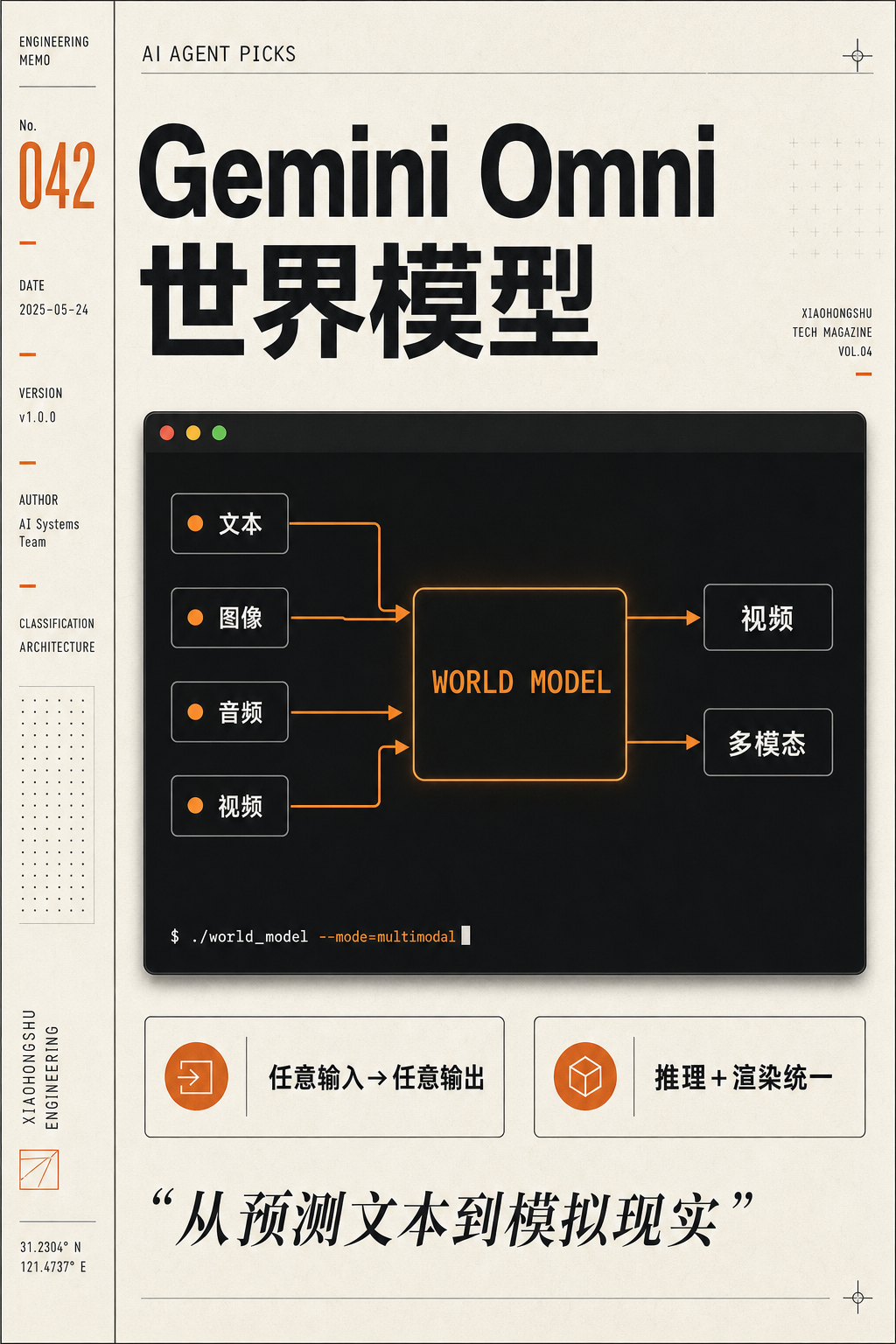
谷歌在 I/O 2026 上发布 Gemini Omni,一个不只是「生成视频」的模型——它推理物理规律、理解文化语境、让教授在黑板上推导正确的数学证明。当 OpenAI 的 Sora 已成历史,Omni 用「任意输入→任意输出」的架构宣告:视频生成的竞争进入了「世界模型」阶段。

发生了什么
2026 年 5 月 19 日,Google I/O 2026 开幕日,Sundar Pichai 在 X 上发了一条推文:
Gemini Omni doesn't just build scenes that look real, it reasons about what should happen next.
这句话精准概括了 Omni 的本质——不是让画面「看起来对」,而是让画面「逻辑上对」。
发布会前一天,两条 Omni 生成的演示视频已经在 Reddit 和 X 上炸开了锅。一条是教授站在黑板前推导三角恒等式——数学推导过程完全正确,不是视觉上的公式拼贴,是符号层面真实成立的数学证明。另一条是两名男士在海边餐厅安静地吃意大利面。
看起来平平无奇的日常场景,为什么让技术圈集体破防?
因为这两条视频同时做到了三件事,而这三件事在之前的视频生成模型里从来没有同时成立过:推理对了、空间关系对了、时序对了。教授写板书的同时,口头讲解的正是他正在推导的步骤,语音和画面帧级同步。
Google DeepMind CTO Koray Kavukcuoglu 在官方博客中说得很直接:「Omni combines Gemini's intelligence with our generative media models.」这不是一个 Veo 的升级版,是把 Gemini 的推理能力和渲染能力熔到了一个模型里。
关键数据
| 维度 | Gemini Omni Flash | 对比参照 |
|---|---|---|
| 输入模态 | 文本 + 图像 + 音频 + 视频 | Sora(已关停)、Veo 3.1(文本+图像) |
| 输出模态 | 视频(首批),后续开放图像+文本 | 主流竞品仅支持视频输出 |
| 视频时长 | 10 秒(首批) | Veo 3.1 原生 8 秒,延长后 16 秒 |
| 部署渠道 | Gemini App + Google Flow + YouTube Shorts | Sora 仅独立 App |
| 订阅门槛 | AI Plus / Pro / Ultra 用户 + YouTube Shorts 免费 | Sora 需 ChatGPT Pro |
| 水印 | SynthID 不可见水印 | Sora 无水印方案 |
| API | 未来数周内开放 | — |
| Pro 版本 | Omni Pro 计划中(性能跃升版) | — |
| 内部模型 ID | bard_eac_video_generation_omni | 确认为独立模型,非 Veo 变体 |
深度分析
1. 不只是视频生成,是「世界模型」
Omni 的核心卖点不是「视频更清晰」或「时长更长」——这些是 Veo 3.1 的升级路线。Omni 卖的是「理解」。
DeepMind 产品总监 Nicole Brichtova 说的那句很关键:「It's the next step towards the progression of combining the intelligence of Gemini with the rendering capabilities of our media models.」翻译过来:Omni 把两个系统合成一个了。Gemini 负责理解世界(物理规律、文化背景、历史知识),媒体模型负责渲染画面。
效果体现在哪儿?给 Omni 一句「claymation explainer of protein folding」,它生成一段定格动画风格的视频,配旁白解释蛋白质如何从氨基酸链折叠成三维结构——生物学知识是准确的,不是视觉上「看起来像科普」的胡说八道。
再比如那个经典的弹珠滚轨道视频:弹珠的加速度、碰撞反弹、动能转换——物理过程全部合理。这不是靠训练数据里碰巧有类似的视频,是模型内部建立了一个关于「物体如何运动」的内部表征。
Pichai 在 keynote 里的原话点明了方向:「With world models, AI is moving from predicting text to simulating reality.」从预测文本到模拟现实——这是 AI 叙事的一次级别跃迁。
2. 对话式编辑才是杀手锏
Omni 的第二个核心能力是多轮对话式编辑。你不需要时间线、不需要关键帧、不需要 After Effects。直接说「把雕塑变成气泡」或者「调暗灯光,在手上方放一个玻璃球」,Omni 就改了。
更关键的是:改了之后,上下文不丢。角色的外观保持一致,物理规则继续生效,场景记住之前发生了什么。你可以连续多轮指令:先让小提琴手换个场景,再让小提琴变透明,再换个机位到肩膀上方——每次编辑都在上一次的基础上迭代,不会从零开始。
这个能力直接解决了当前 AI 视频生成最大的痛点:一次性生成可以靠运气,但精确编辑只能靠模型真的理解场景。Omni 的多轮编辑说明它的内部表征不是帧级别的像素映射,而是场景级别的语义理解。
Google 自己定位很明确——面向消费者。Brichtova 说:「Not many video models have breached that chasm with consumers, so this is our play to do that.」研究工程师 Gabe Barth-Maron 更直白:「They're like personalized memes.」
3. 「任意输入→任意输出」的架构野心
Omni 这个名字(拉丁语「全部」)暴露了谷歌的野心。Pichai 说「create anything from any input」不是营销话术,是产品路线图。
第一批只开放了视频输出。但官方已经明确说了,后续会开放图像和文本输出。长远来看,Omni 的目标是一个模型搞定所有模态——从音频生成图像、从视频生成音频、从草图生成完整视频。
这意味着谷歌正在终结当前碎片化的模型布局:Veo 负责视频、Nano Banana 负责图像、Gemini 负责文本——这种架构在工程上本来就不合理。Omni 可能是把这些管线统一的产物。
对竞品来说,这才是真正的降维打击。目前所有顶级视频模型——Veo 3.1、Seedance 2.0、Kling 3.0——都是专门的视频生成器,不具备图像生成或文本推理能力。Omni 是第一个把「全能」写进架构设计的。
但眼下有一个务实的前提条件:Omni Flash 定位偏消费端。真正面向专业用户的 Omni Pro 还没有时间表,Brichtova 只说会在「我们觉得有一个明确的性能跃升时」发布。
4. 填了 Sora 的坑,开了安全的水印先例
OpenAI 的 Sora 在 2025 年关停后,AI 视频生成领域留下了一个明显的真空。主流玩家要么是纯工具(Runway、Pika),要么是实验室项目。没有哪家把视频生成做成了面向数亿用户的消费产品。
Omni 的分发策略值得注意:Gemini App 里直接用、Google Flow 面向创意工作者、YouTube Shorts 免费开放。这不是一个给技术极客玩的项目,是一个要装进所有人手机里的功能。
安全方面,所有 Omni 生成的视频都带 SynthID 不可见水印。用户可以通过 Gemini App、Chrome 中的 Gemini、Google Search 验证视频是否由 AI 生成。Avatar 功能需要专门的身份验证流程——录一段自己念数字的视频,才能创建数字分身。这套机制虽然不能杜绝 deepfake,但至少在产品层面建立了一套可追溯的标记体系。
5. 竞争格局:视频生成从「谁的更好看」变成「谁的更聪明」
Omni 的出现把 AI 视频赛道的竞争维度从「视觉质量」拉到了「世界理解」。
| 竞争者 | 定位 | 优势 | 短板 |
|---|---|---|---|
| Gemini Omni | 全能世界模型 | 推理+渲染统一、对话编辑、多模态输入 | Flash 版时长仅 10 秒,Pro 未定 |
| Veo 3.1 | 专用视频生成 | 成熟稳定,时长可达 16 秒 | 不具备推理能力 |
| Seedance 2.0 | 专用视频生成 | 人物性格鲜明,动作流畅 | 中国市场竞争为主 |
| Kling 3.0 | 专用视频生成 | 视频和音频紧密集成、社交分发 | 扩展能力有限 |
| Luma AI | 广告自动化 | 从简短 brief 生成完整广告 | 垂直场景 |
Omni 和所有竞品的根本区别在那个「Omni」二字。上面列出的每一个都是专用视频生成器,没有任何一个同时具备图像创建或文本推理功能。如果 Gemini Omni 真能把多模态生成统一到一个系统里,它就是独一档的存在。
不过,现实也不全是利好。Omni Flash 的 10 秒时长限制在消费端可以接受,但离专业制作还很远。文本渲染能力虽然 Brichtova 说「pretty proud of」,但编辑 prompt 需要高度具体,否则容易过度编辑或意外改变你想保留的元素——这是 Nano Banana 用户已经踩过的坑。
结尾
Gemini Omni 最大的意义不是「视频生成更好了」,是 AI 第一次在视觉输出中展现出了真正的推理能力。教授在黑板上写对数学证明、弹珠的物理轨迹合理、旁白和画面帧级同步——这些不是「运气好」,是模型内部建起了关于世界如何运作的表征。
Sundar Pichai 说 AI 正在「从预测文本走向模拟现实」。这句话听起来像 keynote 的修辞,但 Omni 证明了他不只是说说而已。